How To Retry Pipelines in Azure Data Factory and Synapse Analytics
In life, things don’t always go well. Sometimes you try, you fail, and you try again. The same is true for cloud networking, specifically in Azure Data Factory and Azure Synapse Analytics. When doing stuff in the almighty cloud, things happen. When they do, you’ll want a self-healing system capable of trying again on its own.
The path to retrying a pipeline varies depending on its trigger type, either tumbling window or scheduled. Microsoft documentation on that can be seen below, and also here.

Tumbling Window Triggers
If you’re using a tumbling window trigger, retry capabilities are built into Data Factory and Synapse. All you’ll need to do is head over to your trigger’s configuration page and set the Retry policy: count and Retry policy: interval in seconds properties to your liking.
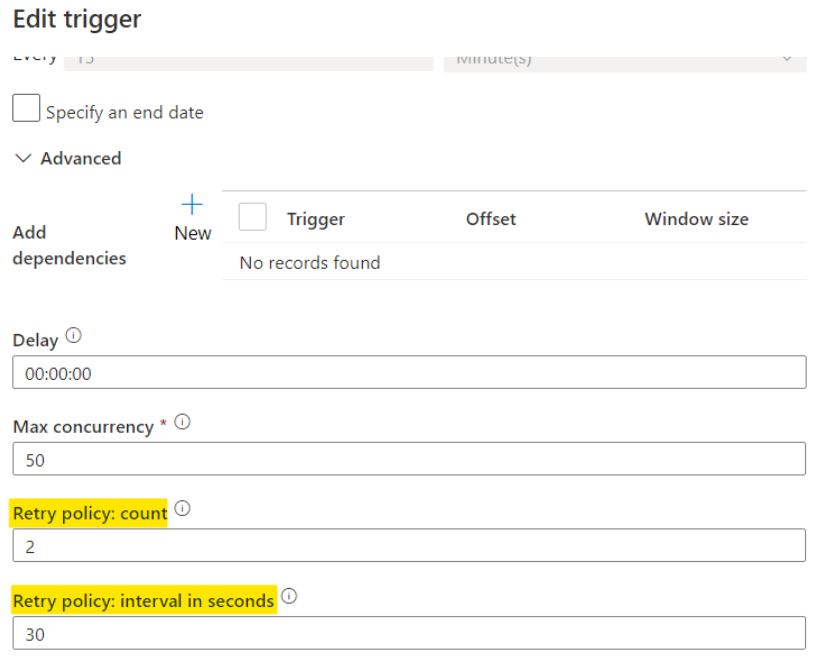
Scheduled Triggers
If you’re using a scheduled trigger to kick off your pipeline(s), you’ll have to get creative with setting up automatic retries. Data Factory and Synapse do not currently support retries on scheduled trigger pipelines, but as with many things in programming, there are some workarounds.
Basic Retry Pattern
The pattern below is a basic implementation of a retry policy for a pipeline that runs on a scheduled trigger in Data Factory or Synapse.
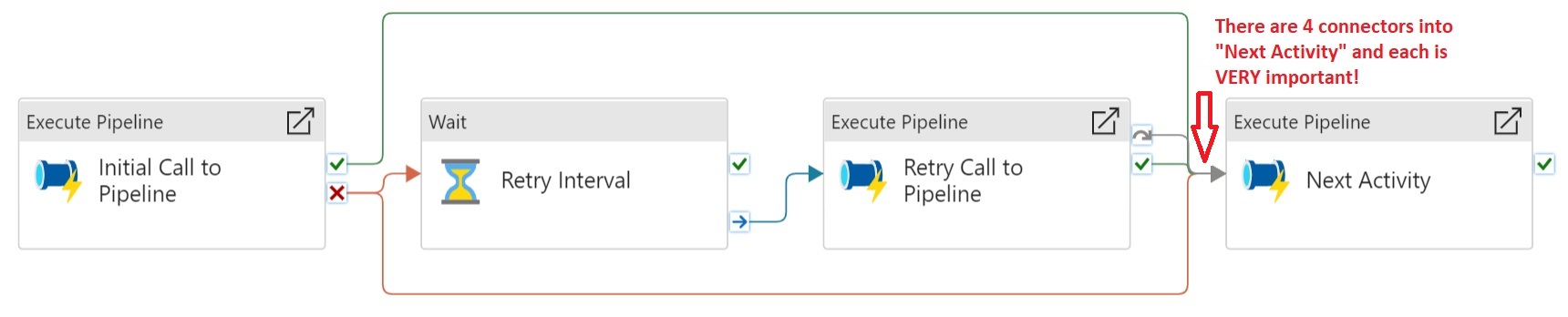
Here’s what’s going on, activity by activity, from left to right.
Initial Call to Pipeline
This is an Execute Pipeline activity containing the original call to the pipeline of note. If it succeeds (green line), we go straight to the Next Activity. There’s no need for a retry if the initial call succeeds. If it fails though, that’s where things get interesting. There are two failure connectors (red lines) coming out of Initial Call to Pipeline. One goes to a Wait activity that tells the pipeline how long to wait before trying again. The other goes straight to Next Activity, just like the success connector. This may seem counterintuitive at first but makes sense upon further review. There are two paths here, one where the initial call fails, and one where it succeeds. If it fails, a retry will occur, and that retry might succeed. If it does, you’ll want Next Activity to run even though the initial call failed. The diagram below conveys the logical paths out of Initial Call to Pipeline
Fails"] --> |retry needed| retryInterval["Retry Interval"] retryInterval --> |waiting complete| retryCallToPipeline["Retry Call to Pipeline"] retryCallToPipeline --> |if succeeds| nextActivity2["Next Activity"] retryCallToPipeline --> |if fails| failEntirePipeline["Fail Entire Pipeline"] end subgraph initialSuccess["Initial Call to Pipeline - Success Path"] direction LR initialCallSuccess["Initial Call to Pipeline
Succeeds"] --> |no need for retry| nextActivity1["Next Activity"] end
The reason why you need to connect Initial Call to Pipeline with two failure connectors, one to Retry Interval and the other to Next Activity, is because of the scenario where Initial Call to Pipeline fails but Retry Call to Pipeline succeeds. In that scenario, you want to run Next Activity despite the failure of Initial Call to Pipeline because the success of Retry Call to Pipeline means you’re good to advance. This is demonstrated visually in Azure Data Factory (or Synapse) by the two failure connectors seen in the screenshot above.
Retry Interval
This is a Wait activity. It waits for a specified period before continuing with the execution of subsequent activities. Here it’s used to establish a retry interval between the initial and subsequent calls to the pipeline. When it completes (blue line) we go to the retry call for the initial pipeline.
Retry Call to Pipeline
This is an Execute Pipeline activity that calls the same pipeline that was executed in Step 1. If this activity is running, it means the initial call failed. It’s very important to note how this activity is connected to the next one. It’s using both a success connector (green line) and a skip connector (gray line). This is because if Initial Call to Pipeline succeeds, it goes straight to Next Activity, skipping Retry Call to Pipeline. If you were to only connect Retry Call to Pipeline to Next Activity on success, what you’d be saying is “only run Next Activity when both Initial Call to Pipeline and Retry Call to Pipeline succeed. But that makes no sense because if the initial call succeeds the retry will be skipped. Therefore, you must connect Retry Call to Pipeline to Next Activity on both success (meaning the initial call failed) and skipped (meaning the initial call succeeded).
Next Activity
This can be any activity that should run after the initial pipeline called in Step 1. It can be yet another Execute Pipeline activity, but if it is and you want to have retries on it, this pattern can get messy
This Basic Pattern Has Problems
Pragmatic programmers have likely already sussed out the scalability issue this pattern has.
What happens when you have several pipelines each in need of at least one retry? For every pipeline needing a retry, you’d have to add at least two additional activities to support this pattern. Seeing as there’s a limit to the number of activities you can have in a Data Factory or Synapse pipeline, this pattern doesn’t scale well at all. Furthermore, what happens when you need to do more than one retry? You’d have to add more Wait and Execute Pipeline activities for every additional retry.
This pattern is all but useless if you’re looking to implement a mature form of resiliency.
Less Basic Retry Pattern
There’s nothing “advanced” about the following pattern, but in comparison to the one above, it supports having multiple retries a lot better. Remember, these are all workarounds. What we’re trying to do is fundamentally simple. Call a function (pipeline), parse the result, and call it again a finite number of times if the initial call failed. Most developers don’t need an article explaining how to implement that logic in their preferred programming language. But when dealing with low-code platforms, sometimes the comically simple becomes surprisingly complex.
This pattern relies on the use of a parent pipeline from which all other pipelines are called. Inside, any child pipelines needing retry logic must be wrapped in an Until activity whose iteration is tied to pipeline parameters and variables. Namely, the following.
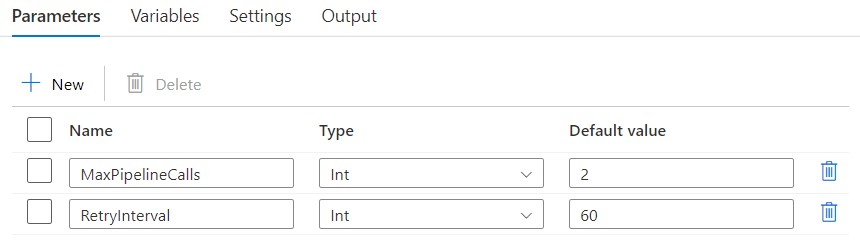
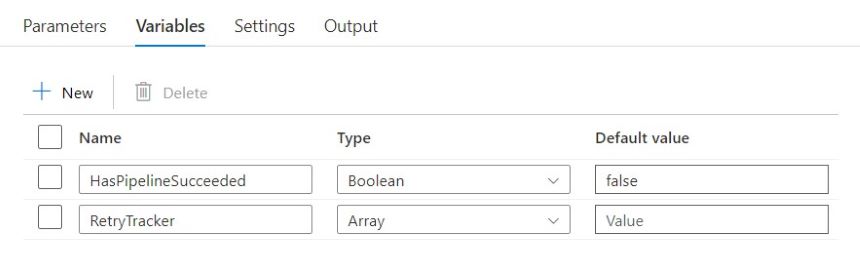
Here’s what each of those is used for.
MaxPipelineCalls: Pipeline parameter. The maximum number of times you want the pipeline to be called. Setting this to 1 effectively means there will be no retries. It’ll be called, and pass or fail, that’ll be it. Any value greater than 1 denotes the desire for retries. Therefore, the number of retries can be calculated asMaxPipelineCalls- 1.RetryInterval: Pipeline parameter. The amount of time to wait, in seconds, between retry calls to the pipeline.HasPipelineSucceeded: Pipeline variable. A Boolean is used to track if a pipeline call has succeeded. Inside of the Until, it’s flipped to true when there’s a success, which signals for the Until to break its iteration. More on that later.RetryTracker: Pipeline variable. An array whose only value is in using its length to track how many retries have occurred. You might be wondering, why not use an integer and simply increment it after each retry? Well, that’s because you can’t do that in ADF and Synapse unless you’re willing to implement some strange workarounds. Instead of nesting a workaround inside of what is already a workaround, I’ve opted for using an array, and an append activity, to track how many retries have occurred. Every time a retry occurs, a value is added to the array, and the Until checks its length against the value ofMaxPipelineCallsto determine if it should break.
Here’s what the pipeline looks like at the highest level. The timeout should be set to something reasonable based on the expected runtime of the pipeline being called.
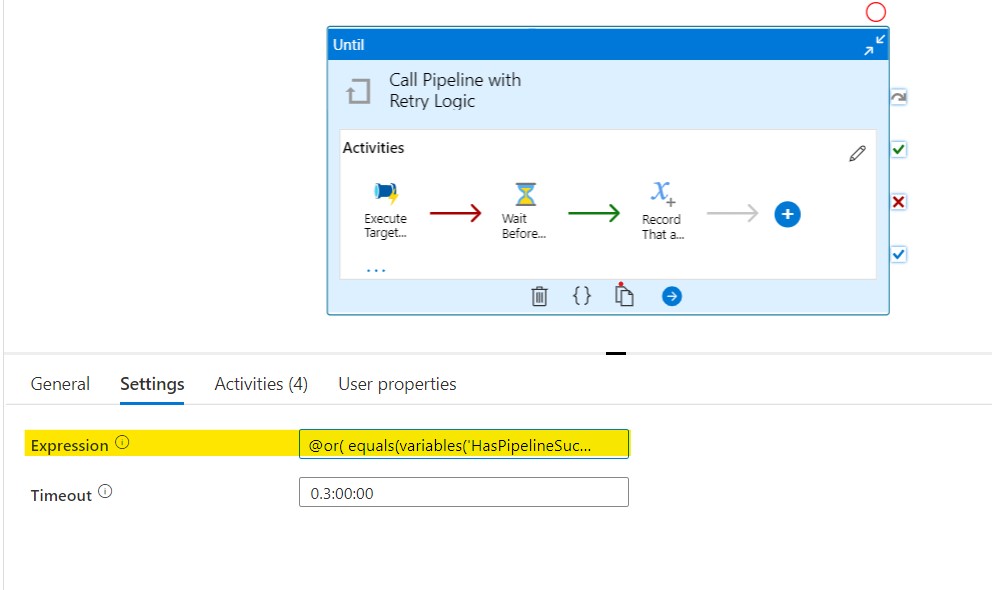
Take note of the highlighted area containing the expression code. It makes use of the aforementioned variables to break the Until when it’s appropriate to do so. The expression code is below.
@or(
equals(variables('HasPipelineSucceeded'), true),
greaterOrEquals(
length(variables('RetryTracker')),
pipeline().parameters.MaxRetries
)
)
Here’s what it looks like inside of the Until.
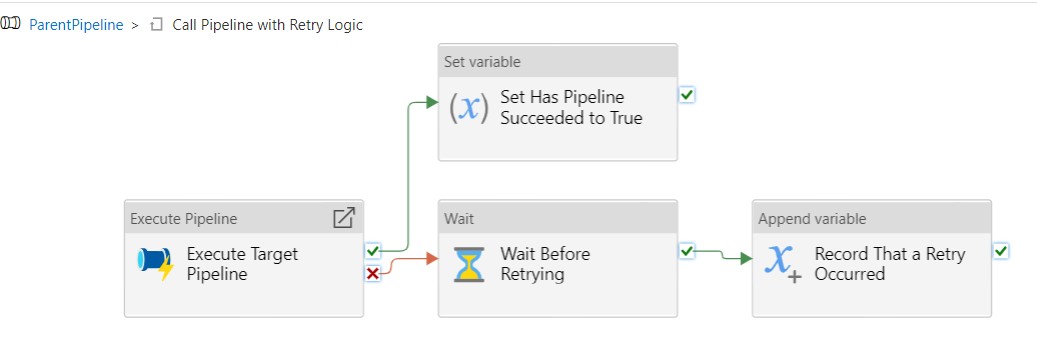
Things start with Execute Target Pipeline which is an Execute Pipeline activity. It calls whatever pipeline needs to have retry capabilities.
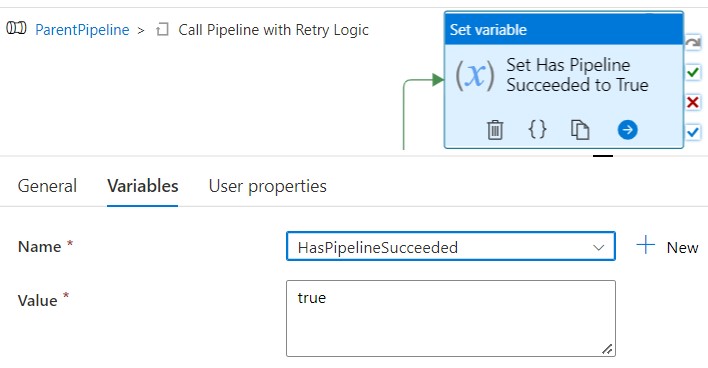
If Execute Target Pipeline succeeds, we go to the Set Variable activity Set Has Pipeline Succeeded to True, which sets the value of the parameter HasPipelineSucceeded, and in so doing, breaks the loop.
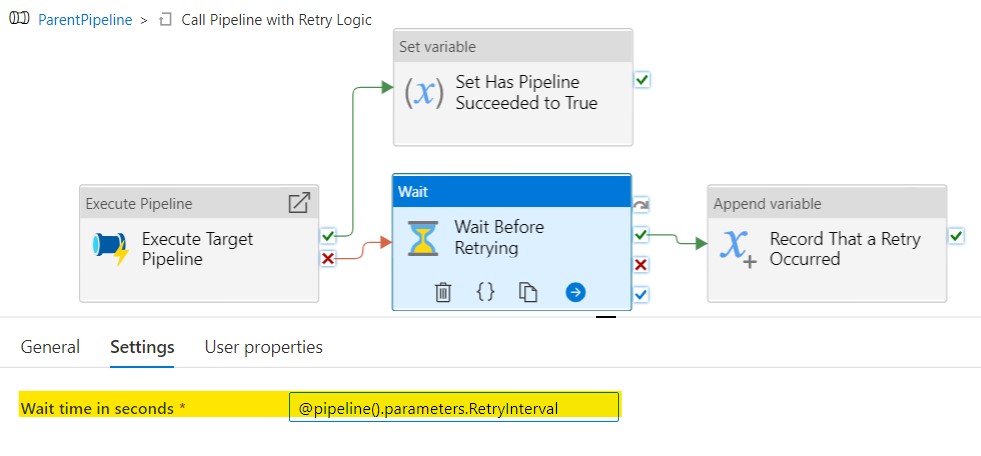
If Execute Target Pipeline fails, we go to a Wait activity that waits according to the value of the RetryInterval parameter.
After waiting, the iteration ends with appending a value (can be any value at all since the count of the array is what we care about) to the RetryTracker array. You might be wondering, why are you adding a dummy value to an array just so you can use its length as an integer? Why not just have an integer that you increment each pass through the loop (Until activity)? Well, that’d certainly make more sense, but in Azure Data Factory, the only variables you can “append” to are arrays. The screenshot below says as much with the message in small text near the bottom. There is another way to work around this, detailed here, but I felt using an array was just less work than adding yet another variable to keep track of. I’m sure the ability to increment integers is coming soon to Azure Synapse Analytics & Data Factory. It has to be, right? Right.
![]()
And so, with a great deal of effort, this pattern provides retry capabilities for pipelines run by scheduled triggers. While it better supports multiple retries, it still kind of sucks. Here’s why.
- Every pipeline needing retries has to be wrapped in its own
Untilthat itself contains 3 additional activities to support the logic. Doesn’t scale well. - Customizing the retry interval and number of retries between distinct pipelines becomes messy. You either need to use the same values for all calls or have separate variables for each pipeline that needs a unique setting.
- Pipeline hygiene can be muddied up by this pattern. All of a sudden your pipeline goes from looking clean and simple to a clutter of chained Until’s existing only to enable retry abilities.
These patterns work, but they’re limited and ultimately not ideal for building an elegantly resilient Data Factory and/or Synapse Analytics solution.
Closing Thoughts
Dear Microsoft, please allow for built-in retries on individual Execute Pipeline activities. You’ve already done a great job with providing that functionality for pipelines being called via tumbling window triggers. I do hereby kindly request that the same feature be brought to pipelines everywhere, indiscriminately, without bias or exclusion. Let there be retries for all pipelines, in all places, in all (reasonable) scenarios, in all Azure regions, no matter how they’re called!
Also, check out this article by Microsoft MVP Meagan Longoria that expertly explains activity and pipeline relationships. Without it, I would’ve never been able to use Azure Data Factory or Synapse Analytics effectively. There was an initiative to get the info from the article onto the official Microsoft documentation site, but alas, it did not succeed. Here’s to hoping that article stays around for the foreseeable future.



